
From a young age I always wondered how things worked. I would take apart toys to see the gears inside. This curiosity led me to programming. I made my first text adventure in batch in 5th grade, and by high school I was president of Senior Division Computer League! I'm a rising senior at Rensselaer Polytechnic Institute, and I'm dual majoring in Computer Science (with a concentration in AI and Data) and Games and Simulation Arts and Sciences. At RPI, I am a Google Developer Student Club Lead and a member of the Computer Science Honors Society Upsilon Pi Epsilon.
Click the image to see each project!
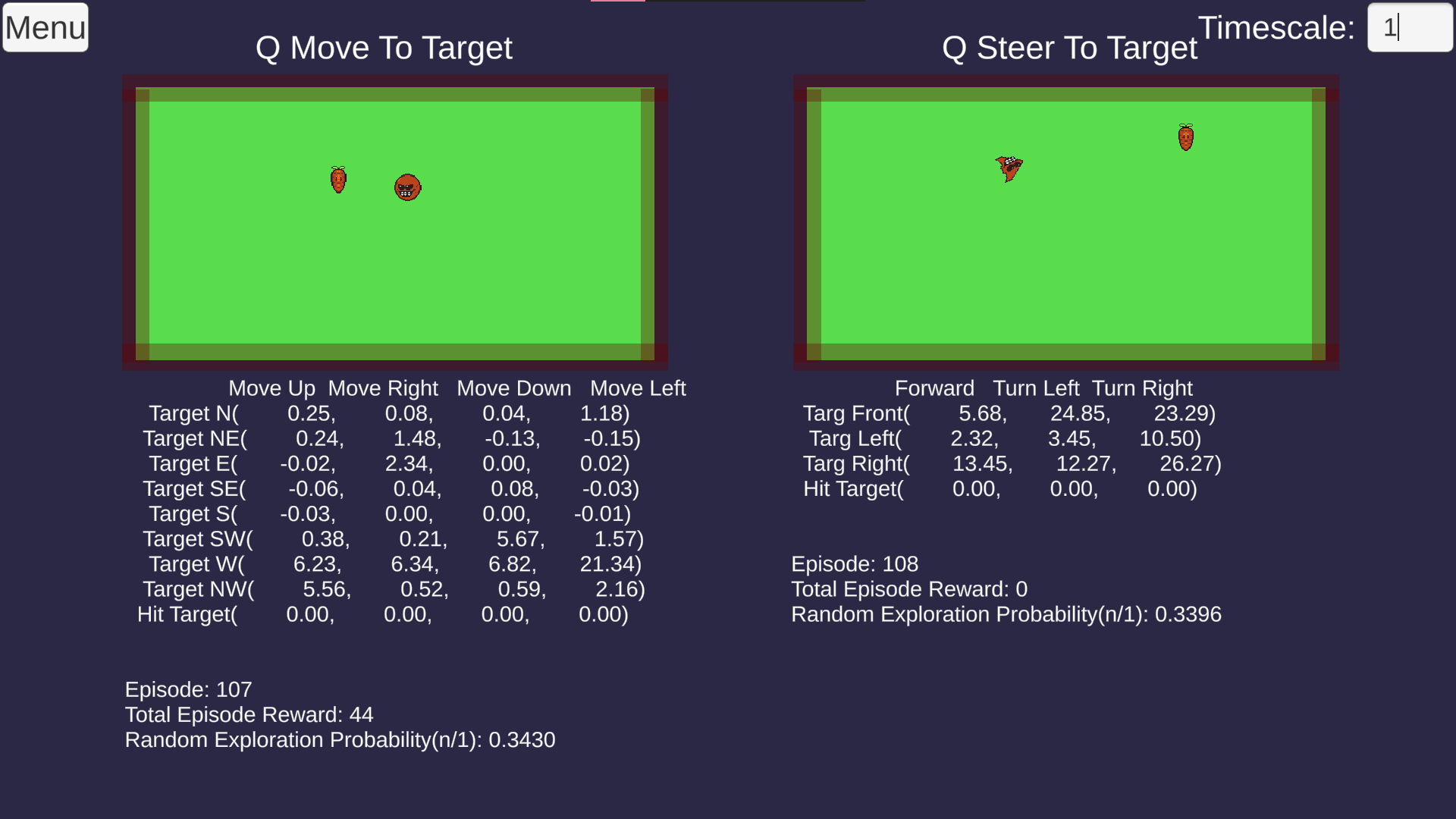
Implemented Machine Learning algorithm Q Learning from scratch in C#. Implementation is flexible and allows for customization of several settings such as number of episodes, episode length, exploration probability, exploration decay, alpha, gamma, number of states, number of actions, etc. Uses object oriented structure, where each agent inherits from a QAgent class and needs to overload GetNextState() and GetReward(). Additional optional overloads include Start(), Update(), Iterate(), OnEpisodeBegin(), and OnEpisodeEnd(). Created demo with 2 agent types and live learning (click the image to see it!).

Created Predator vs Prey simulation using Proximal Policy Optimization algorithm. Both agents are in 2D space and move in all 4 directions. They collect observations for their location, the other agent's location, and 8 raycast sensors. Reward functions reward predator for "catching" the prey by colliding with it as soon as possible. For the prey, reward is higher the longer it evades the predator. Prey must also balance fleeing the prey with collecting its "food." Results of this experiment are documented in a paper linked on the Github repository (click the image to read it!).

Implemented A* pathfinding algorithm for an agent in a 2D grid. Algorithm is fully customizable, with ability to change G and H weights and ability to choose between two distance heuristics (Manhattan vs Euclidean distance). Optimizations of algorithm include removing need for baking grid for a given map by creating the grid in real time during exploration. Agent will try a given direction, but will not include it if it collides with a wall. Client can place new obstacles on the path and the agent will recalculate the path in real time. The algorithm is fully visualized with red dots indicating explored areas and green dots indicating the path. (Click the image to play the demo!)

Implemented movement agents based on the paper "Steering Behaviors For Autonomous Characters" by Craig Reynolds and added additional features such as boids. Agent movement modes include predictive pursue, evade, path follow, and flocking (boids). Obstacle avoidance modes include raycast, cone check, and collision prediction. Features include dynamic obstacle avoidance modes (avoidance mode chosen based on situation, saves computation and gives better results), dynamic (acceleration-based) movement, player movement, and the ability for agents to pursue any transform. (Click the image to play some demos!)
Lorem ipsum dolor sit amet consectetur adipisicing elit. Optio amet dignissimos quidem, voluptatum incidunt eum!